




Step 3. Identifying peptides
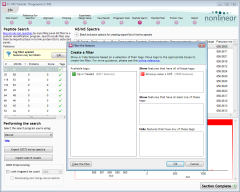 We can now match known peptides to the features we've detected. This is done by using the MS/MS data in the runs.
We can now match known peptides to the features we've detected. This is done by using the MS/MS data in the runs.
Each run contains MS/MS spectra and many of these have already been linked to our interesting features during detection. By using an external search engine (e.g. Mascot) to match these spectra to known peptides, we can identify the peptides in our runs.
Of course, this tutorial can't assume that you're using a particular search engine. Instead, we'll demonstrate all of the steps used to identify peptides, without performing the actual search. When we need to import the search engine's results, we'll use a file that has already been packaged with the tutorial.
First, for simplcity, we'll search for peptide IDs relating to only the interesting peptides. This will keep searches as fast and as relevant as possible:
- Click the Edit... button in the grey filter box above the Features list, at the left
- Make sure that only the Anova p-value ≤ 0.05 tag is selected in the Create a filter window.
- Click the OK button to apply the filter.
Commonly, there are many more spectra than we need associated with each feature. As they will represent the same peptide, we can speed up our search by limiting the number of spectra we identify for each feature. However, we want to make sure we search using the most reliable spectra, so we'll only include the 10 best for each feature:
- Click on the Batch inclusion options expander to display more search options.
- In the Rank option, set the dropdown value to greater than and the enter the number 10 alongside it.
- Click the Exclude from export button (you may need to scroll the batch inclusion options to see this button).
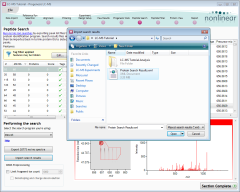 Once we're happy with our search criteria, we perform the actual search. Generally, this is done by selecting the search
program we're using (in the bottom-left corner of the screeen) and clicking the Export ms/ms
spectra button. For this tutorial, we'll skip this and go directly to importing results:
Once we're happy with our search criteria, we perform the actual search. Generally, this is done by selecting the search
program we're using (in the bottom-left corner of the screeen) and clicking the Export ms/ms
spectra button. For this tutorial, we'll skip this and go directly to importing results:
- Select Mascot from the dropdown list under the Performing the search heading.
- Click the Import search results button.
- In the same folder as your experiment, select the Protein Search Results.xml file, as shown in the image at the right.
- Click the Open button to import the results.
When the import process is complete, a message will report how many spectra have been identified. The Features list also updates itself to show which proteins have been found that contain each peptide. For some features, you may find that more than 1 protein identification has been returned. All of this information is available in the Proteins column.
Click the Section Complete button to move to the next step of analysis.
Reviewing the peptide search results
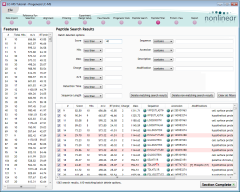 In this tutorial, the organism under study is Clostridium difficile. We can use this information to reject some of the
results from our peptide search. We can also reject results on other more general criteria.
In this tutorial, the organism under study is Clostridium difficile. We can use this information to reject some of the
results from our peptide search. We can also reject results on other more general criteria.
In the Batch deletion options box, do the following:
- Reject search results with poor scores: set the Score parameters to less than and 40, and click the Delete matching search results button.
- Click the Clear all filters button.
- Reject search results based on only one hit: set the Hits parameters to equal to and 1, and click the Delete matching search results button.
- Click the Clear all filters button.
- Reject hypothetical search results: set the Description parameters to contains and hypothetical, and click the Delete matching search results button.
- Click the Clear all filters button.
- Reject search results for other organisms: set the Description parameters to doesn't contain and Clostridium difficile, and click the Delete matching search results button.
We can now be confident that our peptides are reliably identified and are relevant to our experiment.
Click the Section Complete button to validate the search results at the protein level…